
































.png)













































































































































.jpg)














-1754133631392.png--valerio_minato_svela_il_volto_in_movimento_del_monviso_sotto_le_stelle.png?1754133631616#)

































Dal dato all’azione: come PLC e Machine Learning rivoluzionano la manutenzione predittiva


Portare l’intelligenza artificiale direttamente dentro il cuore degli impianti industriali apre scenari entusiasmanti: soluzioni più economiche, flessibili e facilmente integrabili, pronte a rivoluzionare il modo in cui monitoriamo e proteggiamo le nostre macchine.
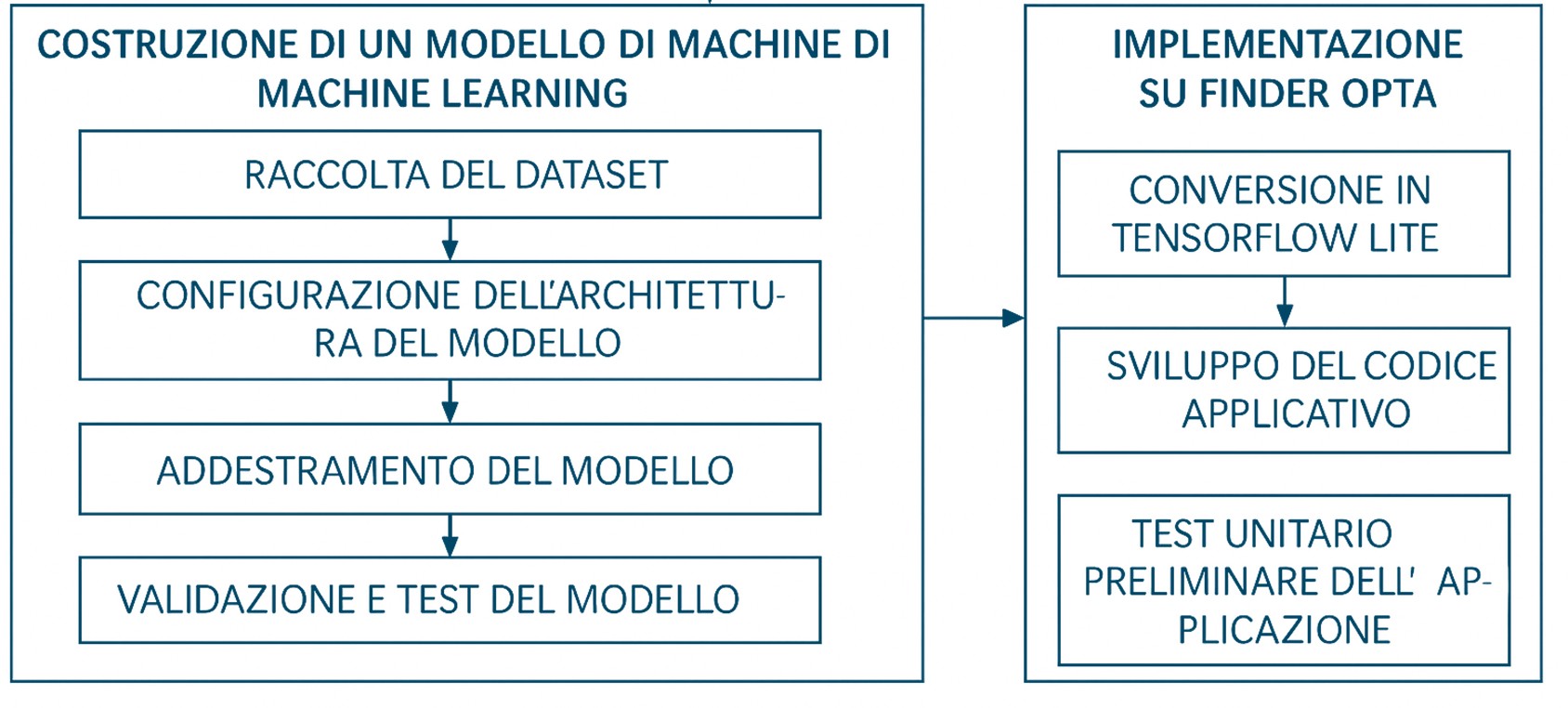
Questa attività, condotta da un team di ricercatori del Politecnico di Torino, nasce come uno studio esplorativo su un’idea sempre più attuale: portare l’intelligenza artificiale direttamente nei dispositivi industriali, e in particolare all’interno di un PLC compatto come il Finder Opta . L’obiettivo? Utilizzare il machine learning per elaborare dati in tempo reale e anticipare i guasti delle macchine, rendendo la manutenzione più intelligente e predittiva.
. L’obiettivo? Utilizzare il machine learning per elaborare dati in tempo reale e anticipare i guasti delle macchine, rendendo la manutenzione più intelligente e predittiva.
Oggi si parla sempre più di “edge computing”, ovvero la possibilità di analizzare i dati “sul campo”, vicino alle macchine, senza doverli inviare a server remoti o al cloud. Questo approccio riduce drasticamente i tempi di risposta, migliora la sicurezza e si adatta perfettamente alle esigenze dell’Industria 4.0, dove velocità e affidabilità fanno la differenza.
Anche se i PLC non sono progettati per compiti complessi di calcolo, questo progetto dimostra che, con le giuste soluzioni, è possibile superare i limiti hardware. In questo caso, una rete neurale convoluzionale (CNN) è stata utilizzata per analizzare segnali acustici e determinare la velocità di rotazione di un banco prova meccanico.
I risultati sono promettenti: il Finder Opta è riuscito a gestire l’intero processo in autonomia, mostrando che anche dispositivi compatti possono diventare alleati preziosi per una manutenzione predittiva avanzata.

Introduzione
L’Industria 4.0 si riferisce all’integrazione dei processi industriali tradizionali con ambienti digitali intelligenti, che monitorando ogni fase del ciclo di produzione migliora la velocità dello scambio di informazioni consente vantaggi quali la riduzione dei costi, la diminuzione dei tempi di inattività, azioni di manutenzione predittiva e proattiva e il miglioramento della sicurezza degli operatori [1-3]. Una delle tecnologie più promettenti in questo contesto è l’apprendimento automatico (ML – Machine Learning), in particolare per quanto riguarda la manutenzione predittiva, dove gli algoritmi ML vengono utilizzati per prevedere i guasti e ottimizzare l’efficienza dei macchinari [4-6]. Il machine learning, e in particolare le reti neurali artificiali (ANN), è in grado di gestire grandi moli di dati ed estrarre relazioni per diventare un prezioso strumento predittivo nella produzione [7]. Tuttavia, l’implementazione di modelli ML in ambienti di produzione tradizionali è difficile a causa degli elevati costi di calcolo e della necessità di un’infrastruttura centralizzata, che richiede investimenti significativi [8]. Una strategia chiave per affrontare queste sfide è “l’edge computing”, che prevede l’implementazione di modelli ML direttamente su dispositivi terminali come i controllori logici programmabili (PLC). Elaborando i dati direttamente su dispositivi come i PLC, “l’edge computing” consente il rilevamento rapido dei guasti, che altrimenti sarebbe impossibile a causa della latenza intrinseca nelle architetture basate sul cloud [9, 10]. Tuttavia, i limiti di memoria e potenza rappresentano ancora una sfida importante per lo sviluppo dell’”edge computing”, soprattutto quando è coinvolto l’apprendimento automatico.
La manutenzione predittiva è uno dei campi in cui l’apprendimento automatico può avere un impatto maggiore [11-13]; questa tecnica rappresenta una via di mezzo tra le strategie “Run-to-Failure”, in cui la manutenzione viene eseguita solo dopo il guasto dei macchinari, e la “manutenzione preventiva”, programmata a intervalli regolari indipendentemente dalle condizioni effettive delle apparecchiature [14,15]. Invece, monitorando continuamente le condizioni di una macchina, la manutenzione predittiva consente di anticipare i guasti ed eseguire la manutenzione solo quando necessario, stimando con precisione la vita utile residua (RUL) e riducendo al minimo i tempi di inattività imprevisti [16].
Questo approccio ha dimostrato di migliorare l’efficienza complessiva delle attrezzature di oltre il 90% [17]. Un aspetto importante della manutenzione predittiva, trattato in questo articolo, è l’uso dei dati acustici, provenienti da microfoni, per il rilevamento delle anomalie. Il rilevamento dei rumori anomali emessi dai macchinari consente di rilevare e identificare i primi segni di guasto [18].
Tradizionalmente, i tecnici esperti erano in grado di identificare tali anomalie con l’udito, ma questo approccio manca di scalabilità industriale, essendo legato all’esperienza personale [19]. L’uso dell’intelligenza artificiale (IA) per il rilevamento di anomalie basato sul suono è un’alternativa promettente, che consente l’automazione di questo processo [20]. Ad esempio, il rilevamento dei suoni basato sull’IA è stato applicato con successo al rilevamento dei guasti nelle macchine di perforazione [21].
Il caso di studio presentato in questo articolo esplora l’implementazione del machine learning per dedurre la velocità di rotazione dei cuscinetti a sfera utilizzando dati acustici registrati da un microfono di classe economica.
Sebbene il caso di studio si concentri principalmente sulla misurazione della velocità di rotazione, l’obiettivo più ampio è lo sviluppo di strategie di manutenzione predittiva nell’ambito dell’Industria 4.0, sfruttando i dati acustici per individuare eventuali malfunzionamenti delle apparecchiature. La scelta di partire dalla misurazione della velocità è motivata dalla semplicità con cui è possibile acquisire segnali rilevabili tramite sensori di base, facilitando così l’addestramento del modello e permettendo un confronto diretto tra i valori previsti e quelli reali.
Tuttavia, questa rappresenta solo una fase iniziale: gli sviluppi futuri del progetto mirano ad ampliare l’applicazione del metodo a scenari più complessi di monitoraggio e diagnostica. Per supportare l’algoritmo di intelligenza artificiale è stato utilizzato il PLC Finder Opta con integrazione Arduino, scelto per la sua economicità e per la facilità di integrazione in impianti esistenti (“retrofit”).
Dimostrando la fattibilità dell’approccio nella misurazione della velocità a partire da segnali acustici, questo studio pone le basi per applicazioni più avanzate, come il monitoraggio strutturale e la rilevazione o previsione di anomalie (ad esempio, perdite d’aria, malfunzionamenti di elettrovalvole, aumento dell’attrito, ecc.) nei componenti e nei sistemi di automazione industriale.
Sviluppo del prototipo di laboratorio
È stato progettato un banco prova sperimentale per valutare la capacità di un PLC di eseguire elaborazioni in tempo reale sulla velocità di rotazione mediante reti neurali integrate, utilizzando come input dati acustici.
La configurazione del sistema è illustrata nello schema in figura 1, mentre una vista d’insieme del banco prova è riportata in figura 2.
Il sistema è composto da un albero rotante, azionato da un motore elettrico asincrono, e supportato alle estremità da cuscinetti radiali a sfere. Originariamente sviluppato per studiare la lubrificazione dei cuscinetti, questo banco si è rivelato particolarmente adatto anche per le esigenze del presente lavoro.
La velocità del motore è regolata tramite un sistema di controllo PID, con alimentazione fornita da un inverter collegato a un’interfaccia HMI (Human-Machine Interface), che consente di monitorare e modificare facilmente i parametri operativi.
Due sono i sensori principali impiegati nell’esperimento:
- un microfono electret ARCELI GY-MAX4466,
- un sensore di prossimità induttivo.
Il microfono rileva i suoni generati dall’albero e dai cuscinetti durante il funzionamento. L’analisi acustica è stata scelta perché particolarmente efficace nell’identificare anomalie meccaniche, come disallineamenti o usura, che si manifestano come variazioni nei pattern sonori. L’uscita del microfono viene preamplificata per migliorarne la qualità e renderla compatibile con l’ingresso ADC (Analog-to-Digital Converter) del Finder Opta, il quale accetta segnali tra 0 e 10 V.
Il sensore di prossimità induttivo, alimentato a 24 V DC, è posizionato vicino all’albero e rileva il passaggio di un piccolo magnete fissato alla sua superficie. Questo consente di effettuare misurazioni accurate della velocità, basate sul conteggio degli impulsi in intervalli temporali definiti. Tali valori costituiscono le etichette di riferimento per l’addestramento e la validazione della rete neurale.
Le coppie di dati, composte dai segnali acustici e dalle corrispondenti letture del sensore induttivo, costituiscono il dataset su cui viene addestrato il modello.
Al centro di questo studio c’è il Finder Opta, un PLC compatto e flessibile sviluppato in collaborazione tra Finder e Arduino. Dotato di un processore ARM Cortex-M dual-core (ST STM32H747XI di STMicroelectronics), il dispositivo è in grado di offrire buone prestazioni con un consumo contenuto di risorse.
La sua architettura industriale è progettata per ambienti gravosi e include numerose opzioni di connettività: Wi-Fi, Bluetooth Low Energy, RS-485 ed Ethernet, rendendolo una soluzione robusta e versatile per applicazioni di automazione industriale avanzata.
Uno dei principali vantaggi di Finder Opta in questo contesto è la sua compatibilità con Arduino, che consente di programmarlo sia con i linguaggi PLC tradizionali (IEC 61131-3) sia con la variante Arduino del C++. Questa doppia compatibilità rende facilmente accessibili le applicazioni avanzate di “machine learning” e IoT. L’ambiente di programmazione Arduino rende disponibili a numerose librerie ufficiali e di terze parti, come TensorFlow Lite per Arduino, che è la struttura di machine learning scelto per questo lavoro, consentendo un rapido sviluppo e una facile integrazione di più tecnologie. L’IDE Arduino ufficiale (versione 2.3) viene utilizzato per sviluppare il software da eseguire su Opta, accessibile tramite la porta seriale USB.
Metodologia e caso di studio
Il flusso di lavoro, illustrato nella figura 3, inizia con la fase di raccolta dei dati, che prevede la registrazione del suono emesso dal banco di prova in funzione, sfruttando gli ingressi analogici dell’Opta per campionare la tensione di uscita dal microfono. Una frequenza di campionamento di 5000 Hz consente di catturare le frequenze rilevanti tenendo conto dei limiti di memoria del PLC.
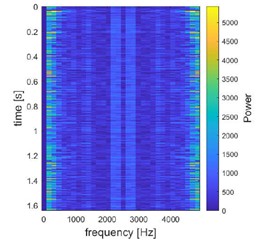
Il sensore di prossimità induttivo fornisce una misurazione accurata della velocità di rotazione, producendo i dati di velocità necessari per l’apprendimento. Per costruire un set di dati completo sono stati registrati 1350 campioni audio nell’intervallo di velocità rilevante (200-1500 giri/min con incrementi di 50 giri/min) e in varie condizioni operative in diversi momenti della giornata per tenere conto dei diversi livelli di rumore esterno presenti nel laboratorio. I segnali di tensione grezzi vengono sottoposti a pre-elaborazione sul dispositivo per estrarre caratteristiche di livello superiore. Sebbene sia ipotizzabile alimentare il modello con il segnale di tensione grezzo campionato dal PLC, l’estrazione di caratteristiche significative rappresenterebbe una sfida piuttosto impegnativa per una piccola rete. Invece, un approccio comune nel riconoscimento audio consiste nel fornire uno spettrogramma come input, ovvero una rappresentazione bidimensionale dello spettro di frequenza del segnale nel tempo, un’astrazione di livello superiore con le informazioni più utili [22].
La trasformata FFT è stata applicata ai segmenti del segnale audio per costruire i loro spettrogrammi, grazie alla libreria ArduinoFFT (v 2.0.2). Gli spettrogrammi offrono un formato a matrice 2D, con un asse che rappresenta il tempo e l’altro la frequenza (figura 4). Questo formato consente alla rete neurale di riconoscere sia i modelli temporali che quelli di frequenza, fondamentali per distinguere tra diverse velocità di rotazione. Le dimensioni dello spettrogramma sono state impostate in modo da garantire un compromesso tra densità di informazioni e dimensioni. Ciò si traduce in un processo di acquisizione audio della durata di 1,64 s.
È stata utilizzata una rete neurale convoluzionale (CNN) in cui per ogni strato è richiesto un solo tensore di input e output. L’input del modello è un tensore bidimensionale, mentre lo strato di output comprende un singolo neurone la cui attivazione rappresenta la previsione della velocità.
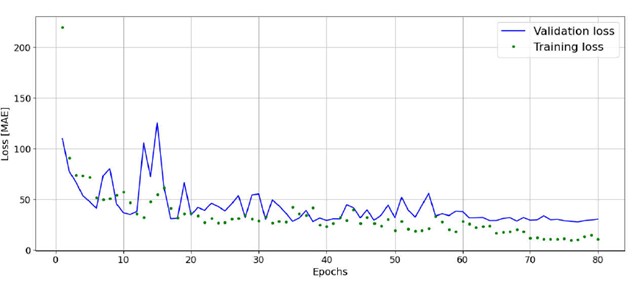
L’addestramento del modello viene eseguito in “Google Colab” utilizzando TensorFlow (versione 2.15.1), sfruttando l’accelerazione GPU per ottimizzare la velocità di apprendimento. Il set di dati raccolti viene randomizzato e suddiviso in set di addestramento, convalida e test, con un rapporto 70%/15%/15%, per valutare e ottimizzare le prestazioni del modello. Ciò viene eseguito in Google Colab con la libreria “Python numpy”. Per il calcolo della perdita, viene scelta la metrica dell’errore assoluto medio (MAE) per la sua robustezza nei confronti dei valori anomali che possono derivare dal rumore estraneo nei dati acustici. Inoltre, il MAE fornisce una visione più equilibrata, evitando la ponderazione sproporzionata dei valori anomali che possono derivare dal rumore nei dati acustici [23]. Questa scelta è in linea con gli obiettivi della manutenzione predittiva, dove la robustezza al rumore e l’accuratezza sono prioritarie. In figura 5 è riportato il diagramma dell’errore assoluto medio MAE ottenuto durante l’addestramento del modello.
Il modello addestrato viene convalidato sul set di test, ottenendo un errore di previsione medio di 28,7 giri al minuto. Il modello finale ottenuto rappresenta un compromesso tra una buona accuratezza nella previsione del risultato e sforzo computazionale adeguato affinché il modello sia adatto all’implementazione in tempo reale sul PLC Finder Opta in relazione ai suoi limiti di memoria.
Una volta implementato, Finder Opta acquisisce l’audio in tempo reale dal banco di prova tramite il microfono electret. Il segnale viene elaborato sul dispositivo per produrre spettrogrammi che corrispondono al formato di input utilizzato durante l’addestramento del modello. Questi vengono inviati al modello per condurre l’inferenza e ottenere una previsione della velocità. Data la possibilità di rumori estranei negli ambienti industriali, le velocità previste vengono mediate su un intervallo di 10 secondi, mitigando gli effetti delle fluttuazioni temporanee e dei rumori ambientali, aumentando la robustezza.
Risultati
L’implementazione del modello ha prodotto risultati promettenti, convalidando la fattibilità dell’integrazione di applicazioni di apprendimento automatico all’interno di dispositivi industriali con risorse limitate.
Nell’attività sperimentale, il modello ha raggiunto un errore assoluto medio complessivo (MAE) di 42,1 giri/min nell’intervallo di velocità operativo compreso tra 200 e 1500 giri/min. Il MAE dettagliato per ciascuna categoria di velocità, riportato in tabella 1, indica prestazioni costanti senza alcuna tendenza apparente tra i diversi intervalli di velocità. Sebbene la metrica selezionata non consenta una valutazione del segno delle previsioni di velocità, è stato osservato che il modello produce prevalentemente velocità superiori ai valori misurati.
Questa distorsione suggerisce la presenza di fattori sistematici che potrebbero richiedere ulteriori indagini, con una possibile soluzione rappresentata dall’espansione del set di dati di addestramento.
Velocità [rpm] MAE [rpm] Velocità [rpm] MAE [rpm] 200 56.1 900 34.5 250 29.9 950 62.1 300 35.8 1000 36.5 350 28.3 1050 44.0 400 53.2 1100 59.7 450 22.6 1150 42.2 500 36.1 1200 45.0 550 46.5 1250 59.1 600 60.5 1300 41.2 650 29.5 1350 42.0 700 33.4 1400 47.7 750 36.3 1450 40.9 800 45.1 1500 36.3 850 32.2 – –
I risultati sperimentali sono stati raccolti in varie condizioni, inclusi diversi momenti della giornata, per tenere conto dei livelli variabili di rumore ambientale al fine di valutare la robustezza del sistema. L’attività sperimentale è stata condotta nei laboratori di meccanica del DIMEAS con macchine di prova comuni e attrezzature meccaniche utilizzate dal personale durante tutto il giorno e, pertanto, presenta un livello di rumore di fondo paragonabile a quello di un ambiente industriale standard.
L’errore medio indica che il modello ha mantenuto una precisione ragionevole, evidenziando la capacità del modello di filtrare le informazioni irrilevanti, garantendo prestazioni affidabili in ambienti industriali reali. La precisione con cui si sono ottenuti i valori di velocità esclude l’applicabilità di tale metodo in ambienti in cui sono richieste misurazioni precise della velocità. Tuttavia, l’obiettivo non era quello di dare priorità alla precisione, ma piuttosto di studiare il flusso di lavoro e gli strumenti a disposizione e i compromessi necessari per implementare modelli di “machine learning” su piattaforme con risorse limitate in previsione di ulteriori ricerche nel campo della manutenzione predittiva. Questo obiettivo è stato raggiunto con successo.
Conclusioni
Questo studio ha dimostrato con successo la fattibilità dell’implementazione di un modello di “machine learning” su PLC per la previsione in tempo reale della velocità di rotazione di un albero, consentendo di esaminare gli strumenti disponibili e il flusso di lavoro richiesto per l’implementazione di ML su PLC, ed aprendo la strada a futuri progressi nella manutenzione predittiva su dispositivi “edge”.
Le prestazioni costanti del modello in condizioni di rumore variabili confermano la sua robustezza e affidabilità, fondamentali per le applicazioni industriali nel mondo reale.
L’implementazione di modelli di “machine learning” su PLC esistenti offre un’alternativa economica alle tradizionali soluzioni centralizzate basate su cloud. La minima infrastruttura aggiuntiva richiesta e la possibilità di adattarlo alle linee di produzione esistenti rendono questo approccio altamente scalabile. Gli impianti di produzione più piccoli, che potrebbero non disporre del budget o delle competenze tecniche necessarie per aggiornamenti estesi, possono adottare questa metodologia per migliorare le loro pratiche di manutenzione.
L'articolo Dal dato all’azione: come PLC e Machine Learning rivoluzionano la manutenzione predittiva sembra essere il primo su Meccanica News.
Qual è la tua reazione?
 Mi piace
0
Mi piace
0
 Antipatico
0
Antipatico
0
 Lo amo
0
Lo amo
0
 Comico
0
Comico
0
 Furioso
0
Furioso
0
 Triste
0
Triste
0
 Wow
0
Wow
0




















