




























































































































































































-1754133631392.png--valerio_minato_svela_il_volto_in_movimento_del_monviso_sotto_le_stelle.png?1754133631616#)
































Deep Learning, che cos’è, a cosa serve e perché è importante nella manifattura

Traduzione simultanea del linguaggio, riconoscimento e classificazione delle immagini, analytics e predizioni più accurate, guida autonoma di veicoli e droni: sono soltanto alcune delle applicazioni del Deep Learning, anche chiamato apprendimento profondo. Si tratta di una sottocategoria del Machine Learning (apprendimento automatico), che rientra nella più ampia branca dell’intelligenza artificiale, dove l’apprendimento si basa sull’assimilazione di rappresentazione di dati (appresi attraverso l’utilizzo di algoritmi di calcolo statico), invece che su algoritmi per l’esecuzione di task specifici.
Deep Learning, che cos’è e in cosa differisce dal Machine Learning
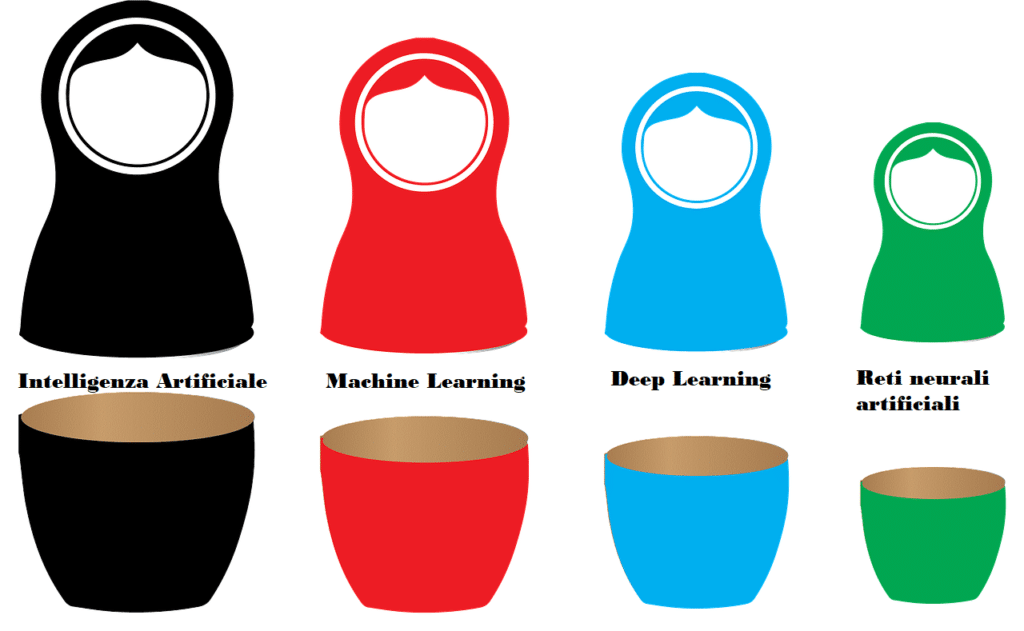
Proprio per la correlazione del Deep Learning con il Machine Learning e l’intelligenza artificiale, questi termini vengono spesso usati impropriamente come sinonimi, quando invece si tratta di tre concetti molto diversi. Per rendere la correlazione tra le 3 più semplice da comprendere, si potrebbe immaginare a una classica matrioska russa, dove l’intelligenza artificiale rappresenta la bambola più grande che contiene le altre.
Come già anticipato, l’apprendimento profondo fa parte della branca dell’intelligenza artificiale, cioè quella tecnologia informatica in cui si fornisce alla macchina una qualità di calcolo che gli permette di compiere operazioni e ragionamenti complessi che, fino a qualche anno fa, erano prerogativa dell’uomo.
Il Deep Learning è una modalità di apprendimento che rientra nel Machine Learning, ma si basa su un processo di apprendimento molto diverso. Nel Machine Learning, infatti, l’apprendimento richiede un pre – processamento dei dati: se prendiamo ad esempio i sistemi di riconoscimento visivo basati sull’apprendimento automatico (visione artificiale), al sistema vanno fornite le caratteristiche di un oggetto (che vengono selezionate manualmente, richiedendo quindi l’intervento umano) per far sì che la macchina riesca a creare un modello in grado di riconoscere e categorizzare gli oggetti, a partire proprio dalle informazioni sulle caratteristiche che gli sono state fornite.
Il sistema, quindi, richiede un set di dati etichettati e un modello di riferimento per capire le correlazioni tra i dati in ingresso e classificarli. A partire da questa classificazione, il sistema potrà eseguire le attività programmate. I feedback forniti dall’uomo sugli errori di classificazione aiutano la macchina nel processo di apprendimento, che basandosi sui riscontri ricevuti continuerà a perfezionarsi.
Nel Deep Learning, al contrario, l’estrazione delle caratteristiche a partire da dati grezzi avviene in modo autonomo, senza richiedere un processo di “addestramento” preventivo: il processo, insomma, non necessita di un modello di riferimento che spieghi al sistema la relazione tra i dati in entrata, ma sarà il sistema stesso a individuarlo.
Questo è possibile grazie alle reti neurali artificiali che, come suggerisce il nome, si basano sul modello della rete neurale biologica, ricreandola grazie a un set di algoritmi combinati tra loro che creano una struttura multistrato.
Cosa sono le reti neurali artificiali e perché sono essenziali per il Deep Learning
Le reti neurali, alla base del processo di apprendimento profondo, sono la struttura che consente alla macchina di processare le informazioni in entrata, elaborarle, selezionare le informazioni necessarie tra le tante ricevute e sulla base di queste giungere a una conclusione, esattamente come avviene nel cervello umano.
Nell’uomo, la rete neurale riceve dati e segnali dall’esterno, attraverso i sensi, che vengono elaborati in informazioni dai nostri neuroni (che costituiscono la nostra potenza di calcolo). Ogni neurone possiede diverse vie di comunicazione in ingresso (dendriti) e una via di comunicazione in uscita (assoni o neuriti). Nel caso che le informazioni in entrata superino un certo valore, il neurone emette degli impulsi in grado di propagarsi nella rete, che sono modulati dai neurotrasmettitori e trasmessi tra un neurone e l’altro attraverso le sinapsi, che possono avere una funzione diversa (eccitatoria o inibitoria) a seconda dello stimolo ricevuto dal neurotrasmettitore.
La rete è quindi una struttura complessa non lineare, dinamica, che ha capacità di adattarsi al contesto (quantità di stimoli e informazioni ricevute): più sono gli stimoli ricevuti e maggiori sono le sinapsi attivate e viceversa. Questo consente alla rete di fornire una risposta più calibrata.
Le reti neurali artificiali funzionano allo stesso modo: sono anche esse strutture complesse e dinamiche, in grado di adattarsi a seconda degli stimoli ricevuti e, proprio come nelle reti biologiche, formate da neuroni in grado di misurare il potenziale dei segnali ricevuti per valutare se è stata raggiunta la soglia di attivazione e, in tal caso, generare a loro volta uno stimolo.
Nonostante i neuroni e le connessioni che si possono stabilire all’interno di una rete neurale artificiale siano migliaia, la struttura della rete può essere definita da 3 componenti:
- lo strato degli input, che riceve ed elabora i segnali in ingresso
- lo strato nascosto (anche qui, il numero varia a seconda degli input ricevuti), dove avviene l’elaborazione vera e propria
- lo strato di uscita, dove vengono raccolti i risultati dell’elaborazione, adattandoli alle richieste del successivo blocco della rete
Le reti neurali, a differenza del deep learning, devono essere addestrate. A seconda del tipo di algoritmi utilizzati, il processo di apprendimento può essere di 4 tipi:
- apprendimento supervisionato, nel quale si fornisce alla rete una serie di input ai quali corrispondono output noti. Dall’analisi di questi dati la rete apprende le associazioni e le regole che le collegano e impara a riconoscerle in automatico nel futuro
- apprendimento non supervisionato, nel quale gli input forniti non vengono manualmente etichettati (ovvero associati agli input di uscita), ma è l’algoritmo a trovare una struttura all’interno dei dati
- apprendimento per rinforzo, basato su un sistema di ricompense e punizioni, dove non esistono associazioni tra gli input in entrata e in uscita e la rete impara attraverso l’interazione con l’ambiente. Stabilita una determinata azione da raggiungere, le azioni che si avvicinano all’obiettivo vengono rinforzate, quelle che vi si allontanano sono invece eliminate. Attraverso questo sistema, la rete impara a distinguere le azioni corrette dagli errori.
- apprendimento semi-supervisionato, ovvero un modello ibrido dove solo ad alcuni input vengono associati altri output, mentre viene lasciato alla rete il compito di trovare i collegamenti tra i restanti input e output.
Come funziona l’apprendimento profondo
Il Deep Learning prende come esempio il processo di ragionamento biologico che viene simulato attraverso le reti neurali artificiali affinché le macchine siano in grado di apprendere in modo più “profondo”, ovvero basato su più livelli, esattamente come avviene nel nostro cervello.
Le reti neurali artificiali sfruttano gli strati nascosti per creare più livelli di astrazione (utilizzano, quindi, più di un algoritmo): ad ogni strato si aggiungono informazioni e analisi utili per fornire un output affidabile e la rete diventa così in grado di imparare a risolvere problemi complessi di riconoscimento degli schemi.
Quanti più strati vengono aggiunti (e quindi quanti più dati vengono forniti alla rete) tanto più preciso sarà l’outcome. La scalabilità del Deep Learning è un’altra delle differenze che lo contraddistinguono dal Machine Learning: i sistemi di apprendimento profondo, infatti, migliorano le loro prestazioni con l’aumentare dei dati ricevuti. Contrariamente, i sistemi basati sull’apprendimento automatico una volta raggiunto un determinato livello di prestazioni non sono più scalabili.
Ma come funziona un processo di apprendimento profondo? Per capirlo possiamo fare riferimento al nostro processo di apprendimento, che inizia dall’infanzia. Gli oggetti con cui ci rapportiamo più frequentemente nella nostra realtà e che sono ora così familiari un tempo erano realtà sconosciute che abbiamo imparato a classificare sotto una determinata etichetta (casa, sedia, cibo, mare e così via), riconoscendo caratteristiche specifiche e basandoci sulle conferme e smentite che ci giungevano dagli adulti intorno a noi (proprio come nell’apprendimento per rinforzo).
Allo stesso modo, anche un sistema di deep learning ha bisogno di una base su cui iniziare, ovvere delle etichette: l’unico intervento necessario da parte dell’uomo in questo procedimento è proprio quello di etichettare i dati, ovvero di inserire meta tag a dati specifici (ad esempio, il tag “sedia” nell’immagine contenente una sedia), senza insegnare al sistema come riconoscere l’elemento da un altro.
Sarà il sistema stesso, attraverso livelli gerarchici multipli, ad apprendere cosa distingue una sedia da una casa, da un uomo e così via. Per far sì che l’output sia quanto più affidabile e preciso possibile occorrono grandi quantità di dati. A questo si deve aggiungere la complessità della struttura della rete, che rende il training ancora più complicato.
Importante, nella fase di addestramento è il ruolo degli algoritmi di backpropagation, ovvero di retropropagazione dell’errore. Questi vengono utilizzati per rivedere le connessioni tra i neuroni della rete in caso di errori: grazie a questi algoritmi la rete propaga all’indietro l’errore per rivedere le connessioni tra i neuroni, fino a che non si ottiene l’output ottimale.
Architetture avanzate e dataset per il training
Il cuore del deep learning risiede nella varietà delle architetture di rete neurale che si possono utilizzare, ognuna adatta a specifici compiti industriali.
Ecco alcune delle architetture avanzate più rilevanti:
- Convolutional Neural Networks (CNN): particolarmente efficaci nell’elaborazione di immagini, sono alla base dei sistemi di visione artificiale per il controllo qualità e l’identificazione dei difetti nei processi produttivi.
- Recurrent Neural Networks (RNN) e Long Short-Term Memory (LSTM): ideali per analizzare dati sequenziali o temporali, come quelli derivati da sensori industriali in applicazioni di manutenzione predittiva.
- Transformer: architetture più recenti nate nel campo del Natural Language Processing, oggi adattate per compiti complessi di analisi multimodale e previsione su dati eterogenei, grazie alla loro capacità di gestire relazioni a lungo raggio e parallelizzare l’elaborazione.
La scelta dell’architettura è determinante per ottenere buoni risultati: ad esempio, una CNN può essere perfetta per l’ispezione visiva, ma è inadatta a prevedere l’usura di un macchinario basandosi su serie temporali.
Training e dataset
L’efficacia di un modello di deep learning dipende fortemente dalla disponibilità di dati di alta qualità per l’addestramento.
- Dataset industriali: esempi noti includono MVTec AD (per l’anomaly detection su immagini industriali) o SECOM (per la classificazione di difetti). Tuttavia, molte aziende generano internamente i propri dataset attraverso sensori e linee di produzione.
- Etichettatura e pre-processing: i dati devono essere accuratamente etichettati, puliti e normalizzati. La fase di etichettatura è spesso costosa e richiede competenze specifiche di dominio.
- Data augmentation: tecniche come la rotazione, il rumore, o il cropping delle immagini aiutano a migliorare la generalizzazione del modello.
- Synthetic data: in mancanza di dati reali sufficienti, si utilizzano dati sintetici generati da simulatori o modelli 3D, particolarmente utili in fase di prototipazione.
Durante il training è fondamentale monitorare metriche come accuratezza, perdita, precisione e richiamo, per garantire che il modello non sia affetto da overfitting e che abbia una buona capacità di generalizzazione.
Queste componenti rappresentano il fondamento su cui costruire soluzioni affidabili e scalabili di deep learning per il settore manifatturiero.
I campi di applicazione del Deep Learning
Grazie alle reti neurali e alla loro capacità di analizzare dati quali immagini, video, audio e serie temporali, il deep learning sta attirando sempre più interesse ed è oggi utilizzato in diversi contesti. Tra i principali campi di applicazione troviamo:
- sicurezza IT. Grazie al Deep Learning, l’efficacia delle misure di sicurezza dei sistemi IT può essere aumentata notevolmente. Infatti, a differenza dei sistemi basati sul Machine Learning, quelli di Deep Learning non identificano soltanto le minacce conosciute, ma anche quelle sconosciute, che vengono rilevate dal sistema come anomalie del modello di riconoscimento della rete neurale
- identificazione delle frodi. Le soluzioni antifrode basate sul Deep Learning sono in grado di identificare i truffatori seriali che modificano le proprie abitudini per evadere i controlli e di creare modelli predittivi e avanzati, che si adattano a contesti nuovi e sconosciuti
- assistenza clienti (chatbox). Grazie al Deep Learning, i chatbox sono in grado di riconoscere il linguaggio umano e interpretarlo, rendendo l’interazione uomo-macchina molto più efficace e il livello di assistenza offerto decisamente migliore
- creazione di contenuti (didascalie, articoli, saggi ecc). Attraverso l’apprendimento profondo è possibile creare sistemi in grado di creare sistemi in grado di imparare a scrivere in una determinata lingua, apprendendone la grammatica, la punteggiatura, l’ortografia e perfino diversi stili di scrittura. Inoltre, è anche possibile creare sistemi in grado di replicare la scrittura manuale umana
- assistenza vocale. Gli assistenti vocali che conosciamo, come Alexa, Siri e Google Assistant, si basano su algoritmi di apprendimento profondo per migliorare le proprie prestazioni a seconda delle richieste e dei comportamenti dell’utente
- medicina e biologia. Gli ambiti di applicazione del Deep Learning in questi ambiti sono molteplici, dal riconoscimento dei tumori dei raggi X, all’aiuto nelle diagnosi, al supporto nell’identificazione di sequenze genetiche di virus e malattie, alla creazione di farmaci “personalizzati”
- mobilità. Grazie alla possibilità del Deep Learning di elaborare 20 miliardi di operazioni al secondo, i veicoli a guida autonoma hanno fatto grandi passi in avanti. Questi veicoli utilizzano la computer vision (o visione artificiale) per riprodurre la vista umana e sono in grado di riconoscere gli elementi presenti nell’ambiente intorno a loro per muoversi in sicurezza
- industria, dove il deep learning viene impiegato nei robot collaborativi che affiancano gli operatori nelle catene di produzione e assemblaggio e nella manutenzione predittiva.

Applicazioni nella manifattura
Il deep learning sta trasformando in profondità il settore manifatturiero, introducendo nuove capacità di automazione, ispezione e previsione che erano impensabili solo pochi anni fa. Ecco alcune delle principali aree applicative, arricchite con esempi concreti e trend emergenti.
Controllo qualità con visione artificiale
Grazie alle reti neurali convoluzionali (CNN), è oggi possibile automatizzare l’ispezione visiva di componenti e prodotti con livelli di precisione superiori a quelli umani. Sistemi di deep learning sono impiegati per identificare difetti superficiali, microfratture, anomalie geometriche o contaminazioni.
Un esempio rilevante è rappresentato da Bosch, che ha implementato soluzioni basate su deep learning per il controllo visivo su linea, riducendo drasticamente il tasso di scarti e migliorando l’affidabilità complessiva del processo.
Il sistema ViPAS ha permesso l’ispezione automatizzata di componenti elettronici grazie a modelli CNN addestrati su dataset di immagini industriali.
Manutenzione predittiva
Integrando dati provenienti da sensori IoT (temperatura, vibrazioni, acustica), modelli di deep learning riescono a identificare pattern anomali che anticipano guasti o degradi prestazionali. Ciò consente di pianificare interventi manutentivi mirati, riducendo i tempi di fermo macchina e ottimizzando l’efficienza operativa.
Siemens, ad esempio, utilizza tecnologie di deep learning all’interno della sua piattaforma Industrial AI per monitorare le turbine industriali e prevedere anomalie con settimane di anticipo. Il sistema si basa su analisi predittive multi-variate e reti neurali profonde applicate ai dati sensoriali.
Ottimizzazione della produzione e analisi predittiva
Modelli di deep learning sono in grado di analizzare dati di produzione eterogenei per suggerire miglioramenti nei parametri di processo, rilevare colli di bottiglia o prevedere la resa qualitativa in base alle condizioni operative. Questo approccio supporta il paradigma della “fabbrica adattiva”, capace di autoregolarsi in tempo reale.
Robotica avanzata e automazione cognitiva
Il deep learning consente ai robot industriali di acquisire capacità percettive avanzate, come il riconoscimento visivo e la presa di oggetti deformabili o irregolari. Permette poi lo sviluppo di sistemi collaborativi uomo-macchina più sicuri e intelligenti in grado di adattarsi dinamicamente al contesto operativo.
Digital Twin intelligenti
Combinando modelli fisici simulativi con deep learning, i digital twin diventano strumenti predittivi più potenti. Possono apprendere dai dati storici e in tempo reale per ottimizzare l’efficienza, simulare scenari futuri e testare modifiche senza impatti sul sistema reale.
Integrazione con l’edge computing e l’Industrial Internet of Things (IIoT)
Uno dei trend più significativi nell’evoluzione delle applicazioni di deep learning nella manifattura è rappresentato dall’integrazione con l’edge computing e l’Industrial Internet of Things (IIoT). L’obiettivo è spostare l’intelligenza artificiale il più vicino possibile alla fonte dei dati, ovvero ai macchinari, ai sensori e alle linee produttive.
Perché serve l’edge AI? Originariamente i modelli di deep learning venivano eseguiti nel cloud o su server centrali, richiedendo la trasmissione continua di grandi quantità di dati. Questo approccio presenta limiti evidenti in contesti industriali, dove i requisiti di latenza bassa, affidabilità e riservatezza dei dati sono fondamentali.
Con l’edge computing l’elaborazione avviene direttamente su dispositivi locali dotati di capacità computazionali (es. edge gateway, microcontrollori, NVIDIA Jetson, Google Coral), riducendo i tempi di risposta e migliorando l’autonomia operativa.
Deep learning + IIoT: un binomio strategico
L’IIoT fornisce la rete di sensori connessi e di dispositivi intelligenti che generano una mole crescente di dati. Il deep learning consente di valorizzare tali dati per:
- rilevare anomalie in tempo reale
- ottimizzare i parametri operativi
- identificare correlazioni complesse tra variabili di processo
Questa sinergia permette di passare dalla semplice automazione alla manifattura cognitiva, in cui le macchine apprendono dai dati e si adattano ai cambiamenti ambientali e produttivi.
La visione artificiale, o computer vision
La visione artificiale, o computer vision, è un campo di studi interdisciplinare che mira a riprodurre i compiti e le funzioni dell’apparato visivo umano. Riconoscere a identificare le immagini, con i loro compontenti, è soltanto una parte della computer vision definita “elaborazione a basso livello di astrazione”, o early vision.
Nei sistemi di visione artificiale l’immagine viene acquisita attraverso dei sensori che inviano il segnale al calcolatore, che a sua volta li digitalizza e memorizza. L’immagine viene poi “letta” e analizzata dal software a seconda degli scopi di programmazione, confrontata con il modello di riferimento classificato e utilizzata per prendere decisioni.
Questi sistemi si basano sul Machine Learning e sul training della macchina attraverso algoritmi di apprendimento supervisionato e non supervisionato.
La sfida più ambiziosa della visione artificiale riguarda invece la high level vision, ovvero una visione ad alto livello di astrazione che sia in grado, a partire da un’immagine 2D, di elaborare e ricostruire il contesto 3D in cui è inserita. Gli approcci di riconoscimento 3D (3D object recognition) si basano, invece, sulle reti neurali.
Quelle che si sono dimostrate più adatta nella 3D object recognition sono le reti neurali convoluzionali, ovvero architetture di Deep Learning formate da 5 strati in cui ogni strato della rete calcola i valori per quello successivo per una elaborazione dell’informazione sempre più raffinata. Sono, inoltre, reti feed-forward, dove il flusso di informazioni procede soltanto in avanti, dall’input all’output.
Anche la visione artificiale ha molteplici campi di applicazione (come nella telemedicina e nel restauro beni culturali), ma è nell’industria e nel manifatturiero che negli ultimi anni ha trovato uno spazio sempre maggiore.
Deep Learning e visione artificiale nel manifatturiero
I sistemi di visione artificiale hanno una grande potenzialità di utilizzo nel manifatturiero, grazie alla loro capacità di ottimizzare il processo di produzione, migliorare i controlli di qualità del prodotto e aumentare la sicurezza dell’impianto.
Tra le applicazioni troviamo:
- manutenzione predittiva. I robot dotati di intelligenza artificiale e visione artificiale sono in grado di catturare immagini di ogni apparecchiatura e dati relativi ai parametri di funzionamento che aiutano gli operatori a valutare in tempo reale lo stato dei macchinari e contribuiscono a prevenire i guasti, riducendo così i fermi macchina non pianificati
- analisi di qualità dei prodotti lungo la linea. Anche i controlli di qualità dei prodotti sono stati automatizzati e ottimizzati grazie alla visione artificiale. I sistemi basati su di essa vengono infatti utilizzati sia nel controllo del prodotto finito che lungo la linea e inviano i dati e gli eventuali alert di segnalazione dei difetti agli operatori
- veicoli a guida autonoma utilizzati, ad esempio, per spostare le varie componenti lungo la linea, in tutta sicurezza
- scansione e lettura dei codici a barre. Sostituendo gli scanner manuali con sistemi di visione artificiale integrati con funzionalità quali riconoscimento ottico dei caratteri (OCR), riconoscimento ottico dei codici a barre (OBR) e altre tecnologie di elaborazione dell’immagine è possibile ottimizzare il processo e assicurare che tutti i componenti si trovino nella posizione giusta lungo la linea di produzione e nel momento giusto
- migliorare la sicurezza sui luoghi di lavoro. Questi sistemi sono in grado di analizzare l’impianto e i comportamenti degli operatori per segnalare situazioni di possibile pericolo, contribuendo alla prevenzione degli incidenti. Inoltre dotando i robot di questi sistemi è possibile sostituire l’operatore nelle situazioni particolarmente pericolose.
Come abbiamo visto, i campi di applicazione del Deep Learning sono moltissimi. Questa tecnologia ha già rivoluzionato molti aspetti della nostra quotidianità, dall’interazione con il nostro smartphone alla produzione dei beni negli stabilimenti. Un percorso lungo che è iniziato nel lontano 1958 (quando lo psicologo Rosemblatt presentò al mondo accademico la prima rete neurale, il famoso Perceptron) e che sicuramente porterà a molte altre innovazioni nel futuro.
L'articolo Deep Learning, che cos’è, a cosa serve e perché è importante nella manifattura proviene da Innovation Post.
Qual è la tua reazione?
 Mi piace
0
Mi piace
0
 Antipatico
0
Antipatico
0
 Lo amo
0
Lo amo
0
 Comico
0
Comico
0
 Furioso
0
Furioso
0
 Triste
0
Triste
0
 Wow
0
Wow
0

















